
Goodhart's Law and Why Measurement is Hard
The other day, I was failing to teach my 3-year-old son about measurement. He wanted to figure out if something would fit in an envelope, and I was “helping” by showing him how to measure the width of the envelope, then comparing it to the width of the paper he was trying to insert. It turns out that this is a trickier concept than I had assumed; the ability to understand even simple measurements requires a fair amount of cognitive maturity. 3-year-old kids can compare directly, but the concept of using a measure to compare indirectly is more difficult. I finally let him try to fit the paper in the envelope to see it wouldn’t fit.
As with many other cognitive skills, the fact that it’s a counter-intuitive learned skill for children means that adults don’t do it intuitively either. So why are measures used? There are lots of good reasons, and I think a useful heuristic for understanding where to use them is to look for the triad of intuition, trust, and complexity.

Measurement replaces intuition, which is often fallible. It replaces trust, which is often misplaced. It finesses complexity, which is frequently irreducible. So faulty intuition, untrusted partners, and complex systems can be understood via intuitive, trustworthy, simple metrics. If this seems reductive, it’s worth noting how successful the strategy has been, historically. Wherever and whenever metrics proliferated, overall, the world seems to have improved.
Despite these benefits, measuring obscures, disrupts, and distorts systems. I want to talk about the limitations of metrics before expanding on some problems that are created when they are used carelessly, and then show why the problem with metrics — and algorithms that rely on them — isn’t something that can be avoided.
Managers Need to Measure
Measurement is critical everywhere to an extent simply inconceivable in the past. Most systems that are used by humans, or that use humans, are now built around quantifiable attributes. And computers allow us to quantify many things that were previously ignored. (Yet another way in which software is eating the world.) Peter Drucker is quoted as saying, “If you can’t measure it, you can’t manage it.” Like many adages, this is replacing a complex idea with a simple aphorism — and it’s reductive in both good and bad ways.Metrics are popular because they allow people to use measures to make rules — and these rules can often be pretty effective. Systems change in response to incentives, and good metrics let us make rules that create the right incentives to improve. You may not usually think in these terms, but at a high level, all systems respond to the rules and structures that exist. Managing any modern system, whether technical, human, or a bureaucratic mix, is an exercise in understanding the use and pitfalls of now-ubiquitous measurements.
The key problem of using a measure as a metric is sometimes referred to as Goodhart’s law. The law is based on a 1975 paper on economic regulation, and is typically paraphrased as “When a measure becomes a metric, it ceases to be a good measure.” When managing a system, this problem is critical, but is deeper than it at first seems, as I’ll argue.
It’s worth looking at some of the basic failures of metrics in order to understand why Goodhart’s insight is critical. I think these can be understood via the three key things measurement can replace, mentioned above: intuition, trust, and lack of understanding of a complex system. Each of these is a reason to use measurement, but in each case measurement also creates new pitfalls. Measurement sometimes becomes a substitute for good judgement, a way to cover-your-rear, and (my favorite) an excuse for doing fun math and coding instead of dealing with messy and hard to understand human interactions.Measuring and Intuition
The first obvious problem with Drucker’s statement is that we manage the unmeasurable all the time. Liz Ryan rebuts Drucker’s claim in a Forbes article, noting that “the vast majority of important things we manage at work aren’t measurable” — and we do fine.On the one hand, Kahneman found that decisions are subject to cognitive biases and can be systematically improved once we move past our intuition. On the other, despite our systematic biases, as Gary Klein originally noted when studying firefighters, many decisions don’t use metrics, and are incredibly effective despite that. In fact, this success isn’t despite the lack of cognition, but because of it. Klein’s “recognition-primed decision making” works exactly where our intuition beats measurement. As Klein and Kahneman now agree, there are domains in which “raw intuition” beats reflection — and that linked dialog has some great stories about what those are. Does this mean that some things are “unmeasurable”? Douglas Hubbard makes a fairly strong claim not, in his appropriately titled “How to Measure Anything.”
Some domains seem overly reluctant to apply measurements, while others seem to overuse them. Ideally, a balance can be found between using measurements where they add value, and forgoing them when they don’t.
So how do we find where to measure, and where not? We can intuit where it is that our intuition works well, but I’d advise against it. Measuring is valuable because it works as a check on intuition, and as Hubbard notes, it is precisely the areas where no measurement has been done before that his method typically finds tremendous value in creating metrics. He opens the book saying that “no matter how ‘fuzzy’ the measurement is, it’s still a measurement if it tells you more than you knew before.”
His argument is persuasive and important, but to answer the question of where to measure, it relies on a fairly complex methodology for assessing value of information. Without actually applying the full approach, it’s possible to miss the fact that the cost of good enough measurement can be higher than the benefit over using intuition. Not attempting to measure something can be a much bigger mistake than accepting a fuzzy measure — but not always, and I have no simple answers. Just don’t trust your intuition alone on which is which.Measuring and Trust
A kid tells you they are the smartest person in their freshman college class. You don’t know them — but their SAT score can tell you if their claim is plausible. Your gut tells you that Sally is the worst manager you have on your team — but her division’s continued success and low employee attrition rate might tell you a different story. John, a prospective employee, has a sales history that sounds impressive, and statistics to back it up — but that only helps if you trust that the statistics he presents about himself are honest.Using measurements requires trusting the data used for the measurements, and the methods used for transforming the data. Statistics, like any other discipline, is a way to think, but it can’t stop you from lying to yourself, or to others. It can, however, prevent others from lying to you — but only if you trust the source of the data, and understand and trust the methods they used. As the saying goes, “there are lies, and damn lies, and the difficulty of good data collection and the flexibility of statistical methodology obscures the difference.”
Despite this almost obvious caveat, metrics are frequently used in places where this trust is absent. When done correctly, the metrics are objectively verifiable, and the trust needed is minimal. When the FDA asks for clinical trials to be done by companies to ensure that their drugs are safe and effective, it has a slogan it loves using: “trust, but verify.”
Only using metrics you can verify would be great, but there are lots of cases where verification is hard. The obvious, mediocre, and common strategy is to use easy to verify metrics, instead of useful ones. But if we want good metrics, we probably need to collect data — and that is hard to verify from the outside. If someone who produced or has access to the numbers is motivated to fudge the numbers, the dishonesty is difficult to detect.
Perhaps the best way to mitigate the risk of dishonesty is to adopt the strategy testing companies use: create trust through disaggregating responsibility. Test takers are monitored for cheating, graders are anonymized, and the people creating the test have no stake in the game. Strategies that split these tasks are effective at reducing the need for trust, but doing so is expensive, not always worthwhile, and requires complex systems . And complex systems have their own problems.Measuring and Complexity
Until the modern era, complexity was limited by human understanding. Measurement simplifies some of this complexity — and lets it grow past the point where even flawed intuition, or any form of non-formalized trust, is possible. But that means that we now need measurement to control the complex systems we build and participate in.Through the dynamic operation of a system, metrics mold the systems they are created to measure. As Barkides and Cosmides point out, the behavior of a human cultural system (such as a business) is a function of the reciprocal relationship between the system built, and the actions of the people in the system. And none of this is static.
https://twitter.com/willkurt/status/733708922364657664
A metric is a summary statistic, but when the system it is worth summarizing with a metric, it’s worth understanding. As Will noted, the summary won’t replace the article itself, and by reading the blurb instead of the book, you handicap your understanding.
More than that, though, the need for simplification makes management worse, and in addition to molding the system, it warps it. That’s Goodhart’s law — the very use of the metric is what causes the system to change underneath you. Once you look for it, this dynamic is pervasive in any modern human system; measurement is too useful a tool to remain unused, and too powerful not to change the system as it is used. Explaining exactly how this happens, though, is more complex. And complexity ruins everything.Complexity ruins everything
Complex systems have complex problems that need to be solved. Measures can summarize, but they don’t reduce the complexity. This means that measures hide problems, or create them, instead of solving them . This concept is related to imposed legibility, but we need to clarify how in a bit more detail than the ‘recipe for failure’ discussed in the linked piece. In place of that recipe, I suggest another triad to explain how complexity is hidden and legibility is imposed by metrics, leading to Goodhart’s law failures. These failures are especially probable when dimensionality is reduced, causation is not clarified, and the reification of metrics into goals promotes misunderstanding.I hope to convince you that reduced dimensionality of metrics always ignore causality, making the reified goals inevitably create misaligned incentives. That is how imposing legibility on complexity ruins the metrics, causing the system to reinforce failures. To unpack this phenomenon, I’ll provide an example for each element of the triad, then talk about how they work together.
First, metrics reduce dimensionality — the single number of a metric doesn’t represent everything in the system, leading to a loss in fidelity. For example, economics is the study of the distribution of scarce goods. To simplify a couple semesters of economics classes, and leave out the heavy math, let’s assume there are n people, and g different types of good. This means every possible distribution is a point in (n-1)*g dimensional space. (n-1 because that last person gets whatever is left after everyone else has taken.) Each of the n people in the economy can value each of these g different goods differently. The values people place on the distribution are points in a n dimensional space. This is messy — so economists typically make some simplifying assumptions about the shape of people’s preferences, and then decide on some way to aggregate these so that everything can be reduced to a single dimension of social utility. Then, using this simplified metric, they explain how the math proves how to allocate everything.
I’m joking, of course. Economics has some clear impossibility results, like Arrow’s theorem and its extensions, that show why these metrics are not only simplified, but that it is impossible to find a correct metric — there’s no way to distribute things fairly. For economists to keep their well paid academic jobs, these are ignored in order to make things mathematically tractable. Next, they add in some real analysis, allow some separating hyperplanes to let us prove a single optimal equilibrium, and voilà, we have a single function to maximize! And that 1-dimensional social utility function represents something, but it’s pretty hard to understand what.
In any other system, something similar must happen in order to simplify a complex problem into a tractable one. Systems outside of economics don’t (usually) have proven impossibility results, but they certainly lose dimensions in order to make the system understandable. Does it matter? Only when we do something or make some decision on the basis of these simplified metrics.
Second in our list of difficulties is causality. Defining causality is contentious, but I’ll try to keep it simple. A causes B if when we magically manipulate A, but nothing else (even things that would normally change), B changes. This is made harder in practice because usually blaming a single cause is fallacious reasoning.
My favorite example of dissecting causality is from Cosma Shalizi’s amazing course notes, when he talks about about modeling causal relationships. One benefit of the type of visual model he explains is that it is an intuitive representation of a causal structure. Despite being a fairly simple toy example, and using a fairly clear representation, causation is complex, so I’ll take a minute to walk through what the diagram means.
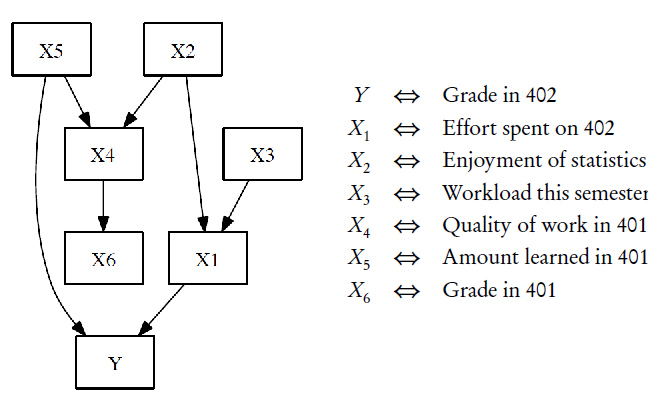
In fact, if you wanted to predict grades, you don’t need causal structure. That’s because for now, grades are a measure, not a metric, and causal structure doesn’t matter. In this case, data from a survey of people’s interest in statistics combined with grades in the previous course would be pretty effective. Measures can simplify the complexity of the causal network.
But we usually aren’t just predicting things with measures. Instead, we want to use the measures as metrics to change the system. In that situation, getting causation wrong is disastrous. Referencing the graph above, you can see that there are plenty of causes that can be manipulated to improve grades: reducing workload will be effective, as will increasing actual learning in the previous course. But if you are only using simple metrics, and which cannot represent the causal structure, it’s irreducible. This is why, as I mentioned earlier, loss of fidelity matters when decisions are made.
Ignoring the causal structure in favor of metrics can lead to clear mistakes. For example, in our toy example, it would be easier to try to increase grades in the earlier course than to ensure learning increased — grade inflation makes students feel better, but if students learn badly in 401, giving them a better grade won’t help them the next semester! This should be obvious; scores measure learning, and changing the score doesn’t change the learning. Despite the relative simplicity, people can get it wrong— metrics are not intuitive enough for us not to slip up occasionally.
The problem exists any time we try to manipulate a metric. We could fix our mistake above by creating grade inflation in 402 — but increasing the metric doesn’t necessarily reflect on the thing being measured. This fact wouldn’t be a problem if we kept it in mind constantly, but this brings us to our third problem: metrics are usually reified.

This simplification is intuitive — unlike the simplification of metrics. Your brain can do less work imagining a full picture than seeing what is actually there. This is a harmless visual effect, but it in less intuitive domains, like measurement, it translates into a reification fallacy. This is when we perceive a pattern or abstraction as if it were a real part of the system. For example, we think of IQ as an actual feature of a person — but it’s not. We accidentally interpret the measure as a real thing, and think of that as, in this case, a property of the person in question.
Does this matter? The Wikipedia article about the Flynn effect is careful to describe the effect as “the substantial and long-sustained increase in both fluid and crystallized intelligence test scores.” Despite the care used in the article to refer to scores, and not intelligence, it’s easy to think that since IQ measures intelligence, higher IQ means higher intelligence. This is relatively harmless, and doesn’t lead to a failure because we’re not yet using the measure as a metric to make any decisions. Another great example of noticing mistaken reification in practice is recently, when Forbes realized that the metric they used for wealth had, perhaps, been a bit mis-calibrated. When the metric doesn’t work, you stop caring about the metric, but continue caring about what it measures.
What’s harmful is that when we create a measure, it is never the thing we care about, and we always want to make decisions. And if you reify metrics away from the true goal, you end up in trouble when they stop being good measures. To bring absolute proof in the form of comics, this is what happens when we decide to teach kids clock repair.
Let me make this concrete. Schools care about test scores, but only because they measure learning. It’s only a measure, until you use it to determine graduation requirements. Investors care about bond ratings, but only because they measure risk of default. It’s only a measure, until you use it to determine capital reserves. Bank regulators care about capital reserves, but only because it is a measure of solvency. It’s only a measure, until you use it to set bank reserve requirements.Principals and Principals
If you aren’t aware of the ideas already, principal-agent problems are how economists discuss the question of how to align multiple parties. Stephen Ross first formalized the clever solution, to you can use a measure of success to align incentives, typically by combining some type of a base payment with a bonus. This solution, however, leads straight to our problem; the bonus must be based on some measure.To pick on education, let’s say educators pick the typical target, and focus on math and reading ability. The problem is that we need a metric to use; children’s math and reading test scores don’t just measure math and reading skill. Instead, the scores measure a complex and interrelated set of factors, spanning more dimensions than we fully understand, and have complex sociological, psychological, developmental, and pedagogical causes. Now — and watch the implicit reification failure — because test scores are used to measure learning, and schools tell teachers to improve learning, teachers need to raise test scores. And as we saw in our discussion of causality, there are lots of ways to do that.
The combination of reification and decisions that use a metric which ignores the causal structure will bite you. Here, it leads to teachers targeting things causally separate from the goal, like teaching test taking skills instead of math. (“Plug each multiple choice answer available into the equation to see which is true. That way, it doesn’t matter that you don’t know how to solve the problem.”)
Metrics frequently act a damaging reification of ill-considered measures of complex goals, and education is as good an example as I’ve seen — though there are plenty of others. Thinking of tests as measuring student achievement is fine, and it usefully simplifies a complex question. Reifying a score as the complex concept of student achievement, however, is incorrect. If the score is used as a measure, and actual goals of education are lost in the mania for testing, then it is a damaging mistake instead of a harmless cognitive quirk.Metrics: Optimizing for mistakes
Systems using measures are incentivized to perform certain ways - they self optimize. Building systems using bad metrics doesn't stop their self-optimization, they just optimize towards something you didn't want. And Goodhart's law ensures that whatever the metric intends to measure won't be quite what is optimized for. And this dynamic keeps coming up, everywhere — it’s not just an education policy issue. Metrics make things better overall, but only occurs to the extent that they are effective at encouraging the true goals of the system. To the extent that they are misaligned, the system’s behavior will diverge from the goals being mismeasured. And once the system diverges, the very incentives you put in place make it hard to change. The problem with Goodhart’s law is that it is impossible to get metrics exactly right, and so the pressure of the system will always warp until the metrics diverge from the actual goal.Specify a metric for user engagement, and as Zeynep Tufekci pointed out in a very worthwhile analysis, Facebook starts to select for sensationalism and garbage. In the article, she says this is because algorithms are not neutral — but I think she’s wrong. Tools themselves are neutral, but how they are used are not. Once we use a neutral algorithmic tool to pursue a goal using a metric, the system is no longer neutral — it’s biased by the metric. So we see that once you specify a metric for reducing recidivism in convicts, you create racial bias. The measure used collapsed the multidimensional goals into a metric that didn’t include fairness, so the system doesn’t make itself fair.
These are not isolated incidents. They are fundamental results of specifying simplified metrics for what you want. But in a complex world, human systems trying to help multiple parties to coordinate can’t avoid using them. Complex systems can only be managed using metrics, and once the metrics are put in place, everyone is being incentivized to follow the system’s logic, to the exclusion of the original goals.
If you’re not careful with your metrics, you’re not careful with your decisions. And you can’t be careful enough.
P.S. See my follow-up post: Overpowered Metrics Eat Underspecified Goals
11 Comments
In the end , there are no facts , because even metrics are based on something non-factual at some limit, and we have to decide what that basis is and if we trust it or not . (So apparent in this election year?--and with all the late night tv commercials about suing big pharma--who despite their so called FDA verification much of it is really based on $$$$$-sorry to be so cynical but I sued big pharma myself in my early 30s and won on the basis of poetry ). I would say Nietzsche was right that "There are no facts, only interpretations."
(- Friedrich Nietzsche (1844-1900)) All metrics are based on us taking something as fact, that may well turn out not to be.
Changing the goal changes the measurement. Changing the measurement changes the metric. Changing the metric changes the decision process. Changing the decision process change the goal. Analysis and performance measurement are about our intentions.
I agree, but the point remains that unless you can build a metric that exactly represents the system, there will be a gap that will widen as the system finds ways to optimize for the metric, instead of the goal. No amount of analysis will overcome the fact that in a complex system, no metric is ever able to fully represent the system, or the intended goal.
great article! I work as an analyst implementing a pay for performance system for a large doctor group. That means it's both designed by doctors and immediately destroyed by those same doctors trying to game the scoring system for a surprisingly small amount of $$.
oh, and NONE of them trust the data.
Most of the troubles of capitalism stem from the fact that money is an imperfect metric for one's overall contribution to society.
I only partially agree; I hope to get back to this point in a future post, tying together my previous post and this one.
These ideas give an organizing framework to, for example, statistics.
Cosma Shalizi's discussion of bootstrapping: http://www.stat.cmu.edu/~cshalizi/402/lectures/08-bootstrap/lecture-08.pdf
or Tucker McLure's discussion of Kalman filters: http://www.anuncommonlab.com/articles/how-kalman-filters-work
might be a lot more memorable (colorful) and more navigable, if they started from this Goodhart's law viewpoint, and sprinkled backreferences throughout, explaining how these techniques have put pressure on our society and institutitions.
In many ways, the ideas stem from insights in statistics; see https://www.jstor.org/stable/1906935 for an early motivator of Goodhart's law.
Great overview! Loved the comic strip about clocks.
This article left a bad aftertaste in my mind and all because of "illusion" pictures. See we see triangles, sphere, pole and plane there because it is there for real. It affects the black geometrical shapes. The unsaid assumption that "whitespace is nothing" is what makes the social gotcha "but there is no real triangle there" to work on gullible minds
In fact this "illusion" can be used as "measurement" in seeing whether person can recognize shapes . I do think a lot of people actually would have trouble to - because it requires exposure to those shapes and their properties, which some people (like say indigenous) might not have. See pure geometry Is a luxury of being exposed to abstract geometry
So overall this article seems like much ado about what? About that we should be careful with metrics and subjects they measure? About a couple of pop-culture memes ("the clock" , "triangle illusion") ? What is the value or insight here?
This is a great article - thank you. I am giving a presentation later this month on Improving Outcomes in my field of medicine (paediatric anaesthesia) & at least some of it will focus on what we do & should use measure as indices of "quality of care". This is really hard, as none of these measures are perfect - your insights into reducing dimensionality & complexity, ignoring causation in complex systems & the danger of reifying metrics (to drive improvements in care) are incredibly helpful. I think healthcare policy & performance suffers from many of the same issues as education.