
Go Corporate or Go Home
If you’re in Silicon Valley, you might have missed the trend, but the percentage of American workers working for big companies has been increasing, even as corporate bureaucracy is getting more stifling. Strangely, this has been happening even as the companies issue press releases about being more flexible and adaptive, to compete with startups, as Paul Graham argues in his recent controversial essay on Refragmentation. But flexible seems to mean layoffs and reorgs into ever more complex and, yes, fragmented corporate structures. They aren’t slimming down into flexible startups.
Worse, startups scale into big companies, and transform into bureaucracies when they do. Harvard Business Review just came out with some advice on how to stop being a startup. Even startups can’t stay startups. Github, the catalyst for distributed software companies everywhere, is itself restructuring. As the author of this post on Github’s restructuring puts it, “Out with flat org structure based purely on meritocracy, in with supervisors and middle managers.” But why?
My basic argument is this: the legibility that lets companies scale is at odds with the flexible way typical startups operate. I see two extremes, with flexibility and legibility on opposite sides — but transitions only happens in one direction. Small companies give up flexibility and illegibility in exchange for growth. Large companies with legible structure and inflexibility, on the other hand, are not typically interested in giving up size and profitability. Meritocracy, a rallying cry for the Silicon Valley startup mindset, only works when merit can be seen and rewarded by management. Merit can only be obvious to everyone when groups are small enough. Once Github passed Dunbar’s Number, there was going to be no way for people to work as one coherent culture — though they grew so fast they reached double that number before the VCs put in someone to bureaucratize and let them scale.
To understand why management does this, we need to see them how they see themselves. And how does the management of an organization represent structure? Org charts.
Databases and org charts
Management structure is its own little world — and the map of management structure is the org chart. These charts used to be a big deal, but by the ’80s, they had shrunk to simple tree structures. Before I explain why these are trees, specifically, I’ll try to explain why the organization is getting simplified, and what the structure of the organization actually looks like.
The pace of change is one explanation, but I think a simpler one suffices: databases now store org charts. If you store the org chart in a database, the database becomes the org chart. And while databases can store arbitrary data like images, they store graph relationships really easily — which means that the storage technology, databases, actually dictates the structure of the company.
In other words, the medium is the message!
But the relationships stored in these databases need not only be relationships between people. Big bureaucratic companies connect employees to managers in an org chart, but also have big contracts with SAP, or other enterprise resource planning (ERP) software vendors. The ERP databases do a lot more than just store org charts, they map the entire system. Good supply chain managers have maps representing each input, source, and vulnerability for their business processes.
Maps are great at increasing legibility, but once they dictate the territory, you have the ‘Authoritarian High-Modernist Recipe for Failure.’ Unlike social systems, managing a business is a case where imposing structure is probably a good idea. If managers don’t dictate structure, they are trying to manage a system that they haven’t made legible, even to themselves!
It’s much easier to manage this map with ERP systems, which store both HR data, and connect products to business lines, workers to the products they make and sell, and so on. These SQL databases, with their structured indexes and ids, allow managers to generate the reports they need — on profit per vendor, revenue per employee, or almost any other metric they might use.
When companies need to change, there are predefined stored procedures in the database for hiring, firing, or even reorganizing — as long as the database structure itself doesn’t change too much. It is true that the pace of change makes the exact details of the chart less stable, but, like the beautiful org charts of old, these structures are legible — they can lend insight to management, because the structure of the database is clear. Sure, switching from simple management to region-based matrix management to job-type matrix management requires some heavy lifting, but still fits within the structure — SAP has you covered. And that’s what matters — a system legible enough to let your ERP optimize your business process. Walmart need to be really efficient at doing its single job, selling products that it buys cheaply, at scale. Adapting might be hard, but the efficiency of having clear reports and being able to optimize revenue per employee is worth it.
{kind=link}
Some “Big Data” startups offer services extracting insight from other companies’ data, but odds are good they don’t collect their own. The big companies have legible, normalized datasets. And the legible data needs analysis once it gets larger than a person can fit inside their tiny 7+/- 2 item brains.
What about the startups, though? With apologies to Paul Simon;
When I think back on all the crap I learned in B-School, it’s a wonder I run startups at all. And the lack of legibility hasn’t hurt me none, ’cause I scribble diagrams on the wall.
Startups can’t afford contracts with ERP vendors. That’s good! They need to be much less structured. Rigid structure doesn’t allow for rapid pivoting, but scribbling on the wall does. The pivoting that startups go through lets them find a niche and build a culture that demands investment into new, risky, and possibly profitable ideas. They thrive on the flexibility that illegible structures permit.
So how do they manage to manage? I suppose startups could use agile NoSQL data stores, which can fit their arbitrary changes pretty easily, but to be honest, only an old-school MBA would want them to write down their org chart at all. If data describing the organization is small enough, it doesn’t need to be legible to be understood — and companies start tiny. Github is big and impressive. Logical Awesome was tiny and quirky. The founders probably sat in the same garage. Want three managers for your first employee, and none for the second? Not a problem! Silicon Valley is fine with polygamanagement, to coin a malamanteau. But at some point, they stop pivoting. The “flat org structure based purely on meritocracy” at github wasn’t just a design, it was also a default. It’s a natural default, well-suited to startups, because the flexibility of illegibility is fantastic.
Flexible meritocracy is easy when you can shift people around as soon as you see they are ready without needing to rely on metrics identifying top performers, or wait for yearly performance reviews and promotion cycles. But this changes as a company grows — probably around the time that management notices it doesn’t know who everyone is. This is inevitable even when they say they are “acting like a startup”. If all an employee needs to do in a “large and complex organization” to be recognized is “ show up and do your job,” as the CEO of American Airlines claims, then management is admitting they value legibility over flexibility.
It is possible to have illegible relationships throughout large companies, but then the companies are harder to manage, no more flexible, and impossible to optimize. Big businesses can’t be unstructured. If they try, they end up neither legible nor flexible. How do you store the org chart data if the relationships are unclear? NoSQL is excellent if you’re a graph theorist working with large datasets, grateful for a structure you can work with — but a manager at a big firm would recoil in horror if they were told that there was no way to find billed-hours-to-product-sales for their division. They need that legibility to decide which division to lay off, so they can be more flexible!
Culture and Social Graphs
So far, I’ve been explaining organizational structure as if though all that matters is that it is the territory of management. In fact, the true structure of a large company exists on three intertwined but conceptually distinct levels, and all of them matter.
First, and most legible, are official chains of command, which are the territories corresponding to org charts (well, they would be if the latter were kept updated), and are what we've been implicitly discussing so far. These exist in legible databases with clear, 1-to-many manager-to-employee relationships, allowing no ambiguity or complexity. They are trees, and if you keep them pruned and streamlined, they slowly grow and bear reliable crops, in the form of steady ROE.
Second are the business processes, which rely on less formal networks. These can also be stored in a database as business process diagrams. Even if codified, they are much less legible, simply because the processes that exist in a business are not always linear, and most people are part of various different processes. If we have the process structure in a database, even if it’s up to date, it wouldn’t be obvious how to normalize it cleanly. Still, these maps can be captured, and probably shift only at clearly defined times. It’s a messy graph at best — not a tree but a rapidly growing thicket full of independent vines, bushes, and weeds. On the other hand, this thicket is where the real work gets done, organically. If the work isn’t easily defined, these networks need to be more flexible than the org chart. That means that, outside of a few slowly changing sectors, like insurance, shipping, or retail, companies won’t even be able to follow the advice to manage along these rapidly shifting, illegible lines.
Third is the culture, built of personal relationships, reflecting the social graph connecting employees themselves. Unlike the first two, it is not an imposed structure, or a response to business needs, but an emergent network, and a loosely defined culture — and this is much less legible, and definitely isn’t captured anywhere. It’s dynamic, messy, and doesn’t allow for clear structure. While the chain of command reflects patterns of responsibility, and informal networks reflect processes, social graphs reflect moods and chance encounters. They also include weak ties, which means that the structure of the social graph can shift over time in unpredictable ways.
No one other than a researcher would even consider trying to represent the constantly shifting culture — and even researchers would be better off extracting it from employees’ texting and social media relationships than asking the company about it. Instead of passively illegible like a business process, personal relationships can be actively cryptic — specifically not public, or weak enough to fail under the stress of definition.
Despite their impermanence and illegibility, cultures matter. Good ones make companies more resilient, more sociable, and increase retention and satisfaction. If the gods of “Company Culture” are appeased with the right mix of bonuses and flextime, they may even magically help with things shareholders care about, like worker productivity and profits. But this happens only because the first two levels exist as well, providing a habitat. Culture is co-extensive with the ecosystem created by the first two levels of the organization structure -- the chain of command and business processes. But rather than being part of the structure of the ecosystem, it is better understood as the activity within it.
Iain M. Banks’ “Culture” series, in part, explores a society without the first two levels. There is no central anything, and everyone does whatever they want. But in such a culture work is voluntary, and rare.
The smaller a company is, the less they need to formalize anything, and the less the three levels — chain of command, business process, and culture — differ. At small scale, you don’t want to formalize. Founders hold the whole thing in their head, and manage everything. If hierarchy exists at all, clear lines of reporting are secondary to the business process. The cryptic social network is obvious to everyone involved, since everyone is already well connected. When a startup is still exploring how it will make money, it can (and must) pivot occasionally, changing the business completely. The loose structure allows it to do so without reorganizing any explicit structures, and the illegible social graph adapts without noticing. Flat unstructured meritocracy works!
Unfortunately, as I noted earlier, this doesn’t scale. If we tried, it would look, at best, like a high school’s social scene. You’d see cliques, relationships that form and dissolve rapidly, and little if any productive work being done, at least by the majority of the students. Startups can hobble along for a while, growing increasingly illegible and messy, especially if given the prospect of a huge payout. You just have to hope that the chaotic emergent social patterns are stable enough so the cheerleaders can keep the football team away from the basketball team long enough for each to play their big games this weekend.
To extend the brief digression into what a startup would look like if we scaled it without adding structure, let’s explore the high school metaphor a bit more deeply.
High Schools, Sex, and Database Design
As noted earlier, only a researcher would try to map a social graph.
A research team interested in the spread of STDs went around a high school and managed to interview 83% of the students, then graphed all the admitted sexual partners that the 573 sexually active students (confidentially) claimed to have with other students (40% of the total number of claimed sexual relationships) over 18 months. They published a paper with the observed social network graphs; .
![Adolescent%20romantic%20network_reviseda[1]](/static/media/2016/03/Adolescent20romantic20network_reviseda1.jpg)
The graphs show a single aspect of the messy social network of adolescents. As with all attempts to map our dynamic third level, it’s incomplete. For example, I’m guessing not everyone was honest. And other than two seemingly bisexual girls, (can you find them on the chart?) no one at the school is admitting to a homosexual relationship — and that’s probably something you’d care about when studying AIDS. The territory is very different than the map as initially imagined, or even than the one discovered by this study. And the map was supposed to be used for modeling and predicting the spread of STDs.
Epidemiologists like the simplicity of compartmental models — they are fantastic as long as the populations modeled are homogenous in the right ways. But the dynamics of STDs among homosexuals, sex workers, and the social graph of these high school students didn’t simplify the way that models assume. (For epidemiology geeks and graph theorists, the mixing graph is probably closer to Barabási–Albert than Erdős–Rényi.) But why was their mental model wrong? As a first guess, they were used to legible patterns that they and their peers form, not the incoherent and unstable ones that emerge from, say, letting adolescents loose in a high school.
I’ll use database structures to illustrate what assumptions went wrong, and then we can try to use the insight to improve our understanding of social and corporate structure — though the example is much more widely interesting, as well.
Most people, I suspect, have an implicit, mental model that considers a relationship an attribute of a person; Person A has attributes height, weight, interests, job, salary, gender, partner status, etc. This model is sufficient for some purposes, but not for representing relationships. Here, I’ll use the insight of someone much more skilled at building database structure, stealing / adapting the well-constructed example that www.twitter.com/qntm wrote about how a database administrator (DBA) reconstructs a database to include gay marriage — brilliantly labeled the Y2Gay problem. This will refactor the mental map of the territory indirectly, by looking at how to refactor the database structure used to store the map.
To start, we have separate tables to store men and women, with links to the corresponding entry in the other table to represent relationships. This means the “partner” entry is restricted to referencing someone of the opposite gender. (“Gender” obviously used to be considered a binary variable, too — but that’s not our point here.) the partner entry might be flagged as either “dating” or “married.” Sometime, probably in the mid-20th century, people shifted mental models. They kept everyone in a single table, with both men and women listed, and a gender.
Relationships are no longer a link between two different tables, with different categories of humans — it’s just a link by each person to another. If we want to preserve “traditional marriage,” (as The Mythical Man Month explains,) it requires having male people marry female people. How do we do that? Instead of requiring a “partner” entry in the opposite gender table, it requires the partner from the people table be restricted to the opposite gender. When gay marriage began to be discussed, the model could simply remove the restriction that the partner needs to be of the opposite gender. At first, they required a flag for “civil union” instead of “married,” but it’s a crude hack, and people moved on. Voilà, we have gay marriage! (Interestingly, in many ways, accepting more fluid gender identities, and gay marriage, is partly a consequence of changing mental models to treat women as people.)
Our change so far is a minor refactoring. Sure, it tells us that marriage can be conceptualized as between two people, instead of a man and a wife. It even helps clarifying that women are people too. (Yes, they can even have attributes like those men have, like jobs, or ambition!) This is a more or less acceptable database structure for representing most people, and most long term relationships — because they are pretty legible already. It’s still not enough to help our epidemiologists, or enough to explain the problems with startups scaling. High schoolers, like those in our study, are more complicated. Obviously we need a more flexible, less legible structure to let us represent and understand their relationships.
For a simple example of why our current structure is incomplete, how do we represent ex-partners? Obviously, it matters for a high schooler — sleeping with your friend’s ex is creating an ex-friend. Who you used to sleep with is an even more critical part of the picture for an STD epidemiologist. To track this, do we need a column for relationship 1..n, each of which has a partner, and a start/end date? A DBA will quickly notice that this doesn’t scale well, and keeping these entries updated and consistent is a nightmare; you could have unconsummated marriages, or accidental polygamy, where, because of a badly performed marriage registry update, multiple people are married to the same person. (And how to we decide who pays child support?)
Instead, we can be more radical in refactoring our mental model, and the equivalent, better normalized database model: we can treat a relationship as independent of the people, and use a new table with attributes that include which people are in it. The new table has two entries for each relationship, one for each participant, as well as a start date, an end date, and a type — so we can include fiancés, marriages, and even one-night flings using the same structure. We now only enforce a simple rule to limit people to one relationship at a time.
But why stop there? Now that we replaced the 1–1 relationship of males <-> females with a decently normalized table structure, why wouldn’t we go all the way to letting relationships have arbitrary structures? If you’re interested in STD transmission, you need to be able to represent what happens; a still-limited database structure is hardly a reason to object. How do we fix it?
We remove the requirement that each relationship be exclusive, or limited to two people. The new, more expansive model works well for showing the high school network, easier to use and keep updated, and much better than the planar graphs of a small slice of time that the researchers created. As the original Y2Gay essay concludes, the new model extends all the way to graph-theory, with arbitrarily complex directed nodes. Any graph, in the mathematical sense, can be represented. This allows a much better model of how people actually have cohabited, and not just in high schools; group marriages, Heinlein-esque line marriages, and the vast panoply of similar structures from history.
Putting all these changes together, we can specify a legible database — but we end up able to represent illegible social networks. It can represent any type of actual relationship, but it can represent arbitrarily complex, implausible structures just as easily. I’m sure there’s someone in the polyamory subculture of Silicon Valley with a PhD in network theory who’s mapping out cool untried graphical structures, since the number of graphs explodes pretty quickly, but the central question isn’t about the graph — it’s what people want, or do, and how adaptive these structures are. What I’ll call pivot culture, which exists in high schools and colleges, doesn’t want or need legibility. But if you’re a lawyer, you need to know who inherits, who pays child support, and who gets hospital visitation rights. Tradeoffs exist between legibility and the freedom of arbitrary structure — so it’s a good thing for lawyers that as people grow up, they decide on more legible relationships.
As an aside, a question that initially bothered me about polyamory was: why isn’t polyamory more widespread, especially among people who aren’t religious or traditional? Yes, there are some scale limits. At the very least, there is a tradeoff between the frequency you can see someone and the number of people involved, but I’m sure there are people who would be happy to juggle 5 or 10 partners. Why isn’t it more common? Why don’t adults keep pivoting, and why is polygamy now relatively rare? Traditional marriage was a good tradeoff for social designers who wanted legible structures, but it’s less obvious why it’s useful for the people. Given that, it’s confusing why so many people nowadays think there is a single “correct” family structure.
I’ll leave that as a question for now, because it should answer itself later, once we figure out why companies don’t stay agile as they scale. The parallel to companies, though, is clear; what social structures work, for what purposes, and why? In order to answer this question, we can refactor companies the way we refactored relationships. Seeing where this works, or doesn’t work, will finally address the question of why org charts are trees instead of some other structure, and answer the original question of why startups need to go corporate or go home.
Legibility happens
Startups typically find a useful business model by starting with an idea, raising cash, then pivoting until they succeed, or fail. If a startup is successful, it starts generating some free cash flow, then gathers enough profit or bamboozles a high enough valuation to buy Time Warner — or get bought by them. Either way, it forms a small part of the Silicon Valley circle of life. I’d call it the standard Silicon Valley model — but as you’re anticipating, it’s a bit self-defeating; once you succeed, you no longer need to pivot.
Observers will notice that any company successful enough to buy or be bought either has gone corporate, or starts tripping over its unmanageable structure, and needs to fix it, or they might as well go home. For these less well-run, less ambitious, or less lucky companies, they fizzle and stay small, or go bankrupt, and the circle of life continues. In either direction, it leads a bit further towards consolidation, not decentralization.
Flat meritocracies are awesome. Can’t an emergent startup culture, full of collaboration and creativity, allow companies to succeed without turning into corporate bureaucracies? To phrase this differently, Peter Pan has more fun, and startups don’t want to grow up. Can’t kids stay kids, and be successful too?
No. This is where the social graph becomes critical. The number of possible social graphs explodes very quickly; 7 people have only 156 possible configurations, 10 have over a quarter million, and by the time you get to 15 people, the quadrillions of possible structures is clearly unmanageable. This means that decision makers can’t understand the impacts of their decisions. Hiring people becomes a mess, since the only way to scale anything is to disrupt this chaotic network. Firing people, or even reassigning them, is worse — it may be removing a key piece of some process a manager, or even the employee, doesn’t notice.
What is the alternative? Simple, legible org charts. (Preferably trees, which are really simple — and I’ll explain why trees are so simple soon.) Simple structures means that decision makers understand the impacts of their decisions.
Refactoring Bureaucracy
We now have laid out some extremes, and pointed out why startup companies inevitably move towards illegibility when they stay organic. If they succeed, it’s because they manage to move from less legible, organic towards corporate. On the other hand, they can fail in many ways; they can fail to become legible when they try to go corporate, and wreck the business doing so, or they can stay organic by failing to impose enough order to enable growth.
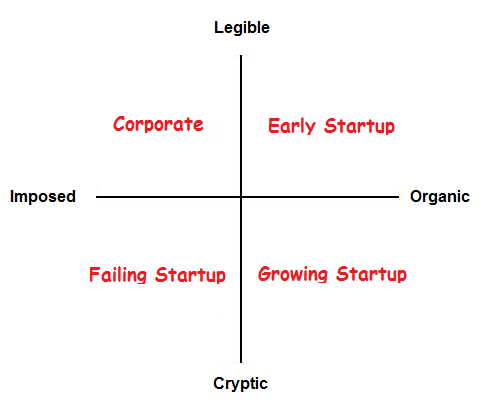
Successful startups generally move from organic and legible towards organic an illegible as they grow, but if they don’t halt the process and impose legibility, they fail. How is this done? The recent piece at HBR that I mentioned at the outset does a great job outlining some strategies. If you’re only interested in scaling a startup, the article is a great place to start, but we can think a bit more about the theory, and how this occurs. There is some more theory I think we can expose here, and I will finally explain why org charts need to be trees.
Graph Theory and Org Charts
The company types in our earlier 2x2 correspond to certain types of org charts — or, in the mathematical sense, graphs. To consider the theoretical possibilities for structuring a company, we can look at what graph structures are possible, and what they correspond to in terms of companies. Here’s a picture to get us started, which uses different, albeit related, axes:
![Screen-Shot-2012-04-05-at-19.26.38[2]](/static/media/2016/03/Screen-Shot-2012-04-05-at-19.26.382.png)
If you don’t know the terminology, don’t worry. The things we care about are mostly visible in the chart, or are about size. The only other thing that matters for us is sparsity, which is just a fancy way of saying a graph has relatively few links between nodes.
We can put many of the types of graphs from the zoo into an analogue of our 2x2, then step through and explain which are useful for companies.
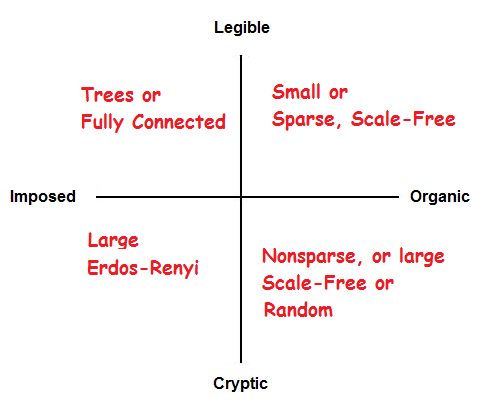
In the top-right quadrant, we start with very small graphs. These are somewhat legible no matter what the structure is — as we mentioned above, early stage startups don’t have structural constraints. Sparse, scale-free networks are also organic and legible even at a somewhat larger size. A healthy startup turns into one as it begins to grow, on the way to getting larger and less sparse. This continues to work at a larger size, up to around Dunbar’s Number, when the company’s organization is sparse — employees don’t need to communicate much across areas. Making org structures less sparse helps with communication as size increase, but it overloads people with too much communication and management responsibility.
Next, in the bottom-right quadrant, we have larger scale-free networks. (“SF-like” in the earlier image). These have legible structure but are organic instead of imposed. I suspect this is the structure of many open source projects. We already mentioned that communication overload makes this stop working if not sparse. If they are sparse enough to allow people to work, they would be interesting as organizational structures, but not as management structures, because they don’t allow central control. This failing makes them anti-corporate, and also probably makes them hard to optimize when you need profitability.
Moving to the bottom-left quadrant, other types of large sparse graphs, ones that are connected artificially, like modular ER-Graphs, are unhelpful for all the previously applicable reasons: communication is hard, there is no coherent leadership, and optimization isn’t possible — you’d only consider them if you care more about network resiliency than efficiency. They might be useful for terrorist cells, but that’s about it.
In the top-left quadrant, before we arrive at trees, we do have another legible, imposed structure. Fully connected graphs are fantastic for communication — everyone talks to everyone else. Unfortunately they are not sparse enough for sanity; everyone needs to be aware of everything else. We already mentioned that it can’t scale as a management paradigm, due to cognitive overload on the part of managers, and Dunbar’s number. (Modern communications allows us to get some of the benefits of connection without the overload, at the social network level. Nowadays, anyone can email the CEO, and it probably isn’t even filtered by their secretary. Despite this, we don’t expect management to happen this way, even if it does make the social graph potentially well connected.)
As we stated earlier, most big companies use tree structures. Now we can suggest a first reason why — most alternatives are unappealing. Slight variations on the theme, however, might be a bit more helpful. We’ll mention them, after a more mathematical detour that further explains why trees are so great.
Computational Complexity of Organizations
This gets even more technical, and you can skip this section, but if you have some familiarity with computational complexity theory…
What’s the computational complexity of most operations on a tree? In computer science terms, it’s O(Log n) -- or in lay terms, ‘not too bad’. Your system still gets slower with scale, but it’s logarithmic, so it can grow without grinding to a halt. Other structures (like lists) might be faster for insertion and deletion, but searching is slower, and we need to do communicate a lot more than we need to change the org structure. Communication can be loglinear with the size of a system, at least as long as your network is a tree.
Why? Legibility is related to ease of communication: if something is legible, you can see where to go and what to do. Every time you need to ask about item X for product Y, you need to find the person in charge of it. But on an arbitrary graph, that’s O(n) or worse. When you need to look at incidence matrices, to know who works with the person you need, since, say, they are out of the office, it’s really bad, O(n · v) — so the less legible the organization is, the harder it is to be resilient. And if you need to optimize, forget it — it’s tree-searches versus traveling salesman problems.
Legibility for Large Structures
We know large bureaucracies are almost always essentially tree-like. They can alter their structure slightly, but not radically simplify. Given this, we would still like to know which variations of treelike structures are useful. Using the theory developed, I’ll describe two of them, and note the graphs that describe them. Of course, both of these are relatively legible and treelike primary structures, and they are never going to allow for unlimited flexibility — they only change the trade-off between robustness and ease of optimization.
First, matrix management lays a slightly less legible layer higher up in the tree. The trade-off allows a bit more flexibility at the top, at the cost of a bit of legibility there. This moves a bit closer to a hierarchical modular structure at the top, trading legibility for those lower down for more connected structure, so that the organization is more fully connected at the upper levels. This means senior managers can all work together as a team, even while those lower down are still stovepiped.
Second, they can create modularity (which is found in social systems) throughout the tree, making it more connected within each area. This trade-off allows a bit more robustness in exchange for a loss in legibility for senior managers. This allows some flexibility in the internal management structures lower down, even if it decreases legibility, making it harder for other parts of the business to work with them.
Legibility for Growth
OK, big organizations will be more efficient if they are tree-like. This limits the endpoints, but there are still many possibilities for getting there. It’s worthwhile to explain how scaling might happen well or badly, and review the process we’ve been discussing from the beginning using the new terminology.
Startups are illegible, with essentially random graphs. This is good for flexibility, and allows meritocracy. The nodes will not be interchangeable, but they are dictated by contingent needs, not structure. You can’t fire the receptionist, he’s the only one who knows how to keep the email server running. Also, no-one else knows how payroll works. The company is flexible, but not scalable. Then the company grows anyways, and that is good for investors, but it is bad for management, which starts imposing structure, or losing control.
As a company scales up a bit, if it wants to be efficient, jobs and responsibilities are shifted around and rationalized. Now the company is partially structured by task or goal, but with a sparse, scale free graph with a high degree of connection and interdependencies between business units. These are not legible, but that’s not too big a deal until the company continues growing. You need someone managing different parts of the company, since it’s now too big to have a single omniscient CEO.
If growth continues without a full overhaul, managers will end up with unclear areas of responsibility, and no way to evaluate or understand the tasks of employees. And you can’t have a meritocracy if you can’t evaluate merit. The company needs to increase legibility.
We’ve explained that a tree is a fairly unique structure for legibility at scale, given our problem constraints. That’s why we see typical corporate structures, instead of varieties, and why startups all face similar scaling problems. Companies will find that other structures, say, for business processes, face a different set of tradeoffs. Not using trees can make more sense when legibility is less critical. That doesn’t mean trees are always optimal even for organizational structure, but it’s at least a good default — and defaults are always more legible, if only because of their familiarity. (This also finally answers the questions about polyamory; typical structures are comfortable, and the simplest structure that allows for a relationship is a dyad.)
Variations on a Theme
Growing startups probably would prefer to modify the emergent structure instead of allowing it to grow unmanageably, or completely replacing it. There are better and worse ways to do this.
A seemingly plausible but bad strategy is worth dismissing; simply actively limiting connections between various areas of a business. This will succeed in reducing connectivity, by leaving only small, emergent subgraphs that are unstructured. This solves one problem, because the company stays sparsely connected overall, and local legibility stays high by making each segment small enough not to need much structure. That helps keep things a bit clearer for management, and it’s known as stove-piping: it makes companies especially inflexible, and everyone despises it.
What is the alternative to stovepiping? A switch to a typical bureaucratic tree-building mode. And that’s what we saw with Github. As the earlier article explained, “Out with flat org structure based purely on meritocracy, in with supervisors and middle managers.” And this is exactly what the HBR article advises; “firms must… add management structures to accommodate increased head count while maintaining informal ties across the organization.”
Conclusion
So now I can repeat myself a bit more, and answer my original question succinctly why don’t companies stay flexible? It’s a necessary result of scaling up and the need for legibility to optimize large systems. We’d love to have flexibility, but the cost is scale, integration, and profitability. For a startup to succeed, it needs to get past the phase where it can be fluid. This isn’t, of course, an iron law — but it’s a reason that we’re not seeing tech visionaries extrapolations borne out in the wider economy. The math of complexity isn’t changing, and humans have cognitive limits. That means we need to accept that growth of companies post-startup phase will not be exponential, nor even linear, but logarithmic — scaling along with the legibility of a tree.
14 Comments
Great companion read to the blockbuster 'Legibility' article of Ribbonfarm :) One quick note: A lot of "innovation focused" teams in corporates would also be part of the bottom left quadrant, ain't it? (The imposed - cryptic area!). What do you think?
Yes, but by thought was that local structures like that are only a slight departure from the overall graph structure; it's adding a (usually small) segment to a much larger, legible graph. It's also usually an attempt to create an emergent subgraph, so it's somewhat more ambiguous. (I agree that it's technically an imposed structure.)
That said, if you are, say, a Chief Innovation Officer, you may wish to have your reports use a different management structure than the rest of the company - but that's an uphill battle, because it reduces legibility for the rest of the company. It also follows the same dynamics as startups; once R&D is a larger department, it needs to become corporate. I suspect that's why most large companies look to acquire innovation: it's easier to bring it inside post-facto, and then try to leave it somewhat alone as a small illegible component. That's also why large acquirers frequently say they want to keep the acquired business as a separate unit - though demands for legibility and integration to align and streamline are hard to resist.
Superb. If "Seeing Like a State" is ever updated, this is the addendum.
What about organizational structures like Holacracy? They seem to embrace the paradox of having a flexible organization that is also legible.
It's interesting, and I'll need to read more - but they may change things materially.
From what I understand, it's only been used in limited contexts, and it and similar models are still going through growing pains as they go though larger scale deployment and are applied in new domains. (I'd love to hear from people at Zappos!) Some interesting points are made here; http://tech.transferwise.com/we-inspire-smart-people-and-we-trust-them/
"That means we need to accept that growth of companies post-startup phase will not be exponential, nor even linear, but logarithmic — scaling along with the legibility of a tree."
Can you explain this conclusion a bit more?
All I know about logarithmic scaling of trees is that balanced trees have depth logarithmic in their size. Depth dominates the costs of operations on trees used as data structures and as communication topologies. The connection to how some aspect of company growth works that you are hinting at isn't clear to me, but it seems like the logarithmic way that tree depth scales lets exponentially larger structures be legible than would otherwise be possible, and is the main advantage of the structure rather than some sort of disadvantage or limitation.
Also, the idea of a minimum spanning tree on a graph seems relevant to the ideas you are developing.
I'm not gong to lay out a huge discussion of communications on graphs, since I'm not as familiar - though it has more to do with coding theory than spanning trees - since even random graphs with low legibility have sparse spanning trees.
That said, I can expand on the point about scaling, which may have been left a bit too vague. Larger companies are less legible, even with great organizations. The amount of cognitive overhead reading these (less legible) organizational structures is inversely proportional to legibility.
In a best case, the difficulty of reading the structures grows only logarithmically with size- if the legibility is maximized. Even then, at the point where that complexity get too high, and the cognitive overhead dominates, there is insufficient legibility to manage well. Large companies already suffer from this, and that's with relatively simple, treelike structures. CEOs of large, complex organizations clearly can't understand everything that is going on, and they can't be brought up to speed on everything simultaneously. This is minimized with delegation and lines of reporting, but that requires legibility, which decreases as the organization grows.
Maybe if you're touching on coding theory there is a tradeoff you have in mind between the complexity of the legibilizing structure and the lossiness of the representation and you're claiming the lossiness drags growth down to being logarithmic in something else?
Yes, but I haven't come up with a good way to formalize my thoughts on the issue.
You missed a homosexual (blue-blue) relationship on the chart. It's towards the right end of the most complex structure.
So I did!
I guess the chart is a bit less legible than would be ideal ;)
David, thanks for your article.
Having worked in large global corporates and recently in a successful unicorn startup, which was taken over by a large global corporate, I have lived through your life cycle of legible, illegible to supposed legible.
During this time I completed a Masters of Strategic Foresight (not an MBA) and a thesis on how an organisation can be legible with scale, while remaining flexible, integrated, profitable, innovative and more. A brief example of this thinking is at http://www.faqsfororgs.com/what-is-the-fundamental-flaw-in-organisations/
The key is to challenge our unquestioned assumption that in order to scale an organization has to be based on vertical functions, sales, marketing, development, service, finance instead of one horizontally aligned to outcomes. This is a Holarchial structure, along the lines of Lean Thinking, which comes from the field of Cybernetics. Not to be confused with Holacracy, which is very different, although I wish Tony Hsieh at Zappos all the best and thank him for his trail blazing. Holacracy is missing the necessary ingredient of Vertical Leverage.
Eden Medina's book, Cybernetic Revolutionaries, Technology and Politics in Allende's Chile, describes how this approach was used to run the entire country of Chile, including all the nationalized industries. The model is called Viable System Model and is written up in Patrick Hoverstadt's book, The Fractal Organization, Creating Sustainable Organizations with the Viable System Model.
And I hope to contribute a little bit at my website of FAQs for Organizations, www.faqsfororgs.com, which includes structure, people, culture and systems.
Thanks again and hopefully we can stop assuming to scale we need to form functional vertical silos instead of organizations based on Horizontal Flow with Vertical Leverage.
Regards,
Rob
These do put a sweet and fruity shine into my day, I must say.
What foods and drinks should I limit or avoid while breast-feeding.
How much is 200 grams of rice
An interesting further discussion of Dunbar's number is here; https://www.lifewithalacrity.com/2004/03/the_dunbar_numb.html